Por Equipo de Contenido el 24 de octubre de 2024
(atualizado el 17 de julio de 2025)
-1.png)
La plataforma Axur ahora cuenta con una solución de Threat Hunting. Esto proporciona un motor de búsqueda muy potente para encontrar amenazas a tu organización basadas en los datos expuestos recopilados por nuestro sistema.
Los criminales están constantemente violando los sistemas corporativos y de usuarios finales, compartiendo estos datos con otros actores de amenazas.
Estos datos pueden ayudar a los atacantes de varias maneras:
- Las credenciales filtradas pueden llevar a los actores de amenazas directamente al entorno tecnológico corporativo. Las credenciales filtradas pueden incluir tokens de sesión que eluden la autenticación multifactor.
- La reutilización de contraseñas permite a los atacantes acceder a sistemas corporativos utilizando contraseñas que se filtraron para diferentes servicios o sistemas.
- Los datos personales expuestos pueden ser utilizados en ataques de phishing o para coaccionar a los empleados para que den sus contraseñas o desactiven la MFA.
- Las tarjetas de crédito expuestas pueden ser utilizadas para pedidos fraudulentos en tiendas en línea, dejando a los comerciantes vulnerables a devoluciones de cargos y quejas de clientes.
Las organizaciones pueden detectar proactivamente las amenazas a partir de datos expuestos. Al extender las investigaciones en curso con una verificación de exposición o crear un proceso rutinario para consultar estos datos, es posible detectar riesgos y mitigarlos antes de que se materialice un incidente, evitando que los incidentes en curso se agraven.
Los datos de amenazas también pueden ser invaluables para la recopilación de inteligencia de seguridad, como al analizar pedidos sospechosos de un cliente o para la seguridad de proveedores. Durante las auditorías de seguridad, la información sobre amenazas y exposición puede ayudar a identificar la fuente de una filtración y confirmar si tu empresa fue violada.
El panorama actual de ciberseguridad es muy desafiante, por lo que es esencial mejorar los procesos con datos e inteligencia de amenazas. Con Axur Threat Hunting, te ofrecemos una herramienta muy potente para mejorar el uso de datos de amenazas en cualquier aspecto de la ciberseguridad.
Axur Threat Hunting: Descripción General
En esencia, nuestra solución de Threat Hunting funciona como un motor de búsqueda que permite investigar incidentes que involucran credenciales expuestas, tarjetas de crédito,URLs y dominios y Anuncios y Búsqueda Paga.
El Threat Hunting se trata de identificar puntos de datos específicos que pueden indicar riesgos, amenazas o incluso incidentes que ya podrían estar en curso.

Para comenzar a buscar, es necesario seleccionar una de las bases de datos para la consulta:
- Credenciales – las credenciales expuestas provienen de filtraciones de datos publicadas y registros de malware infostealer que se comparten rutinariamente por los ciberdelincuentes en la Deep & Dark Web, así como en foros de filtración de datos y otros canales.
- Tarjetas de crédito – Esta base de datos contiene información relacionada con tarjetas de crédito expuestas.
- URLs y Dominios – Esta base de datos permite buscar amenazas de phishing y sitios maliciosos, identificando actividades sospechosas en la web.
-
Anuncios y Búsqueda Paga – Detecta anuncios maliciosos en redes sociales (actualmente disponible para Facebook, Instagram y Threads).
El siguiente paso es ingresar los parámetros y operadores de búsqueda.
Los parámetros permiten consultar puntos de datos específicos en función de los criterios elegidos. Por ejemplo, puedes verificar si un usuario determinado tuvo sus credenciales expuestas o buscar todas las tarjetas de crédito con un BIN especificado.
Hay muchos parámetros de búsqueda disponibles para que puedas encontrar los datos relevantes para ti. Algunos ejemplos están disponibles en la propia página del motor de búsqueda, pero hay aún más parámetros para consultas avanzadas.
Algunos de los parámetros disponibles incluyen:
-
Credenciales: nombre de usuario, nombres de dominio, contraseña (oculta), fuente de la filtración.
-
Tarjetas de crédito: número de tarjeta, número de identificación del banco (BIN), nombre del titular, fecha de la filtración, fecha de vencimiento.
- URLs y Dominios: marcas imitadas, logotipos de empresas, fechas de detección, referencias de dominio, puertos abiertos y registros DNS.
-
Anuncios y Búsqueda Paga – Plataforma del anuncio, estado de verificación del perfil, título sospechoso, descripción interpretada por IA a partir de imágenes y atributos.
Los operadores funcionan de la misma manera que en cualquier motor de búsqueda convencional. Puedes combinar varios parámetros con "O" para que se devuelvan todos los resultados que coincidan con cualquiera de los criterios, o usar "Y" para que los resultados solo se devuelvan cuando coincidan con dos o más criterios.
Toda herramienta poderosa como nuestro Threat Hunting tiene cierta complejidad, pero eso no es un problema aquí. El AI Query Builder puede ayudarte a construir tu consulta, incluso si no estás familiarizado con los parámetros o operadores necesarios. En el prompt de IA, puedes describir lo que estás buscando y la IA creará la consulta adecuada. También puedes ajustar la consulta generada antes de ejecutarla.
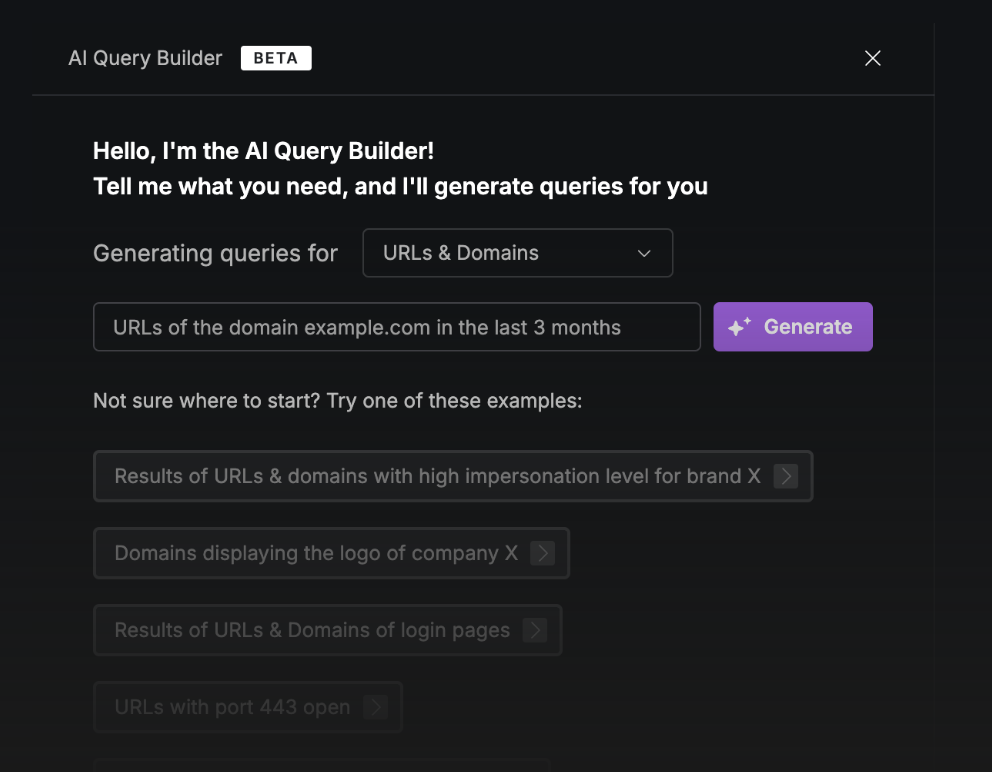
El AI Query Builder es una excelente herramienta tanto para nuevos usuarios como para los experimentados. También sirve para explorar las posibilidades disponibles dentro del Threat Hunting y para aprender nuevos parámetros con los que aún no estés familiarizado.
Los nuevos miembros del equipo pueden ponerse al día rápidamente utilizando el AI Query Builder y aprovechar muchas de las funcionalidades del Threat Hunting de inmediato.
Cuándo y cómo puede ayudar el Threat Hunting
No todas las organizaciones utilizarán el threat hunting de la misma manera. Hay muchas situaciones en las que los datos que ponemos a disposición en nuestra plataforma pueden aprovecharse para ayudar a explicar un intento de intrusión o encontrar la causa raíz de un incidente, pero muchos casos de uso no implican amenazas directas, como al realizar evaluaciones de riesgo para un proveedor o contrato.
Aquí hay algunos ejemplos:
Analizando riesgos
Nuestro Threat Hunting funciona como un motor de búsqueda, por lo que puedes utilizar los datos que ponemos a disposición para muchas tareas de análisis de riesgos.
- Proveedor o cliente: Puedes encontrar datos o exposiciones de credenciales relacionadas con proveedores o clientes. Esto puede usarse al incorporar proveedores, en auditorías o al calcular el riesgo de un contrato.
- Aplicaciones y plataformas: Existen muchas plataformas, aplicaciones u ofertas de Software como Servicio (SaaS) que no ofrecen contratos individuales para cada cliente. El threat hunting ayuda a abordar esto al descubrir filtraciones de datos y exposiciones, proporcionando valiosos insights para la evaluación de riesgos.
- Tarjetas de crédito: Incluso cuando un número de tarjeta de crédito no está disponible, puedes buscar tarjetas de crédito expuestas basándote en el nombre del titular. Esto puede ser usado por tiendas en línea para aprobar o bloquear transacciones sospechosas.
Encontrando la fuente de una violación
La información de los usuarios generalmente se almacena en muchos servicios. Muchos de estos datos están duplicados, y los usuarios pueden reutilizar contraseñas. Cuando ocurren filtraciones, los usuarios pueden quejarse contigo, creyendo que fue tu empresa la que sufrió una violación.
Los datos del Threat Hunting pueden ayudar a descubrir la verdadera fuente de la filtración.
Algunos parámetros que pueden ser útiles para esto son:
- user=email@dominio.ejemplo.com o user=nombre_de_usuario
Devuelve todas las filtraciones de credenciales conocidas relacionadas con la dirección de correo electrónico o el ID de usuario. Los resultados pueden contener información que indique la fuente de la filtración (un malware infostealer, una filtración de datos, etc.). - password=contraseña
Devuelve todas las filtraciones con la contraseña especificada. Puede detectar casos de reutilización de contraseñas.
Detección de fraudes e intentos de phishing
Algunas empresas enfrentan ataques complejos de phishing o sitios web falsos, muchos de los cuales no utilizan explícitamente el nombre de la marca en el dominio o en el contenido. Nuestra plataforma aborda esto detectando incluso las amenazas más ocultas.

Con la búsqueda de "URLs y dominios", los usuarios pueden realizar investigaciones personalizadas que identifican páginas maliciosas basadas en búsquedas de contenido específicas, incluso si la marca no es mencionada directamente.
Puedes investigar amenazas de phishing utilizando varios parámetros, como:
-
Suplantación de marca por elementos visuales: identifica sitios que imitan marcas conocidas o muestran logotipos específicos. Por ejemplo, detecta diferentes niveles de suplantación de "NombreDeLaMarca" o encuentra sitios que muestren el "LogoDeLaMarca".
-
Tipo de contenido y solicitudes de datos sensibles: busca sitios de phishing por tipo de contenido, como páginas de inicio de sesión, páginas de error o sitios de comercio electrónico. También puedes identificar aquellos que solicitan información sensible, como contraseñas o datos de pago.
- Análisis de dominio y ciclo de vida: investiga dominios basados en sus fechas de creación o expiración, o filtra los resultados por fechas de detección recientes para enfocarte en nuevas amenazas.
-
Referencias y atributos de URL: examina URLs o referencias específicas y filtra por atributos de dominio, subdominio o dominio de nivel superior (TLD) para afinar tu búsqueda.
-
Contenido HTML: Busca términos específicos dentro del código de las páginas detectadas, como correos electrónicos, números de teléfono o CNPJs, para localizar campañas falsas basadas en datos conocidos.
-
Indicadores de red y rastreo de origen: identifica amenazas analizando puertos abiertos o rastreando sus orígenes, como recolectores o fuentes de inteligencia de amenazas.
-
Amenazas específicas de idioma y región: restringe tus investigaciones a ciertos idiomas o regiones para identificar campañas de phishing más localizadas.
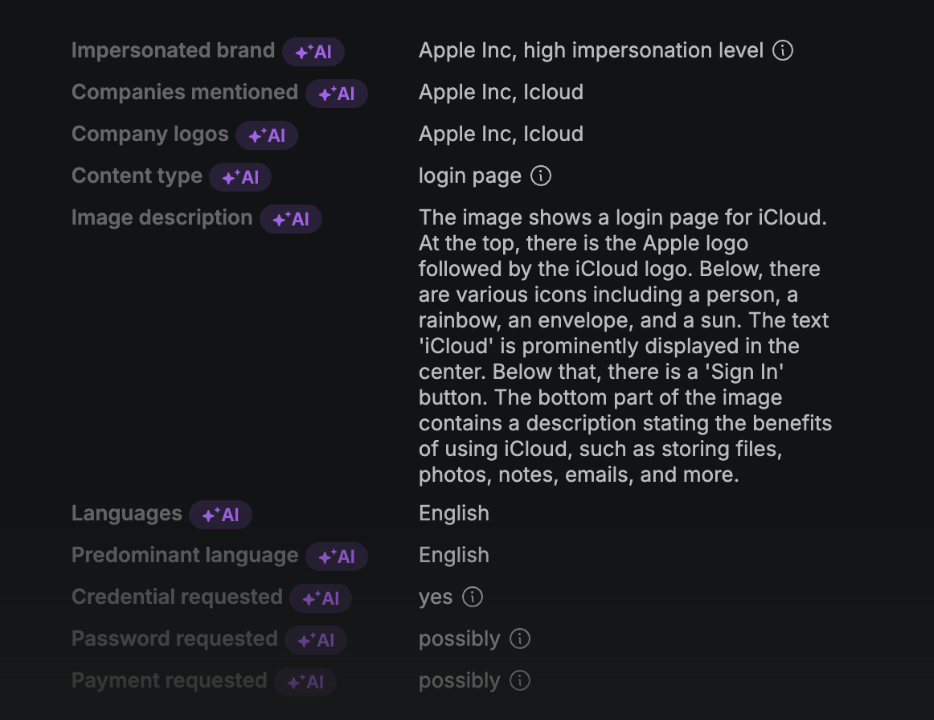
Estos parámetros permiten investigaciones dirigidas, descubriendo sitios de phishing y actividades fraudulentas incluso cuando los indicadores son sutiles.
Detección de anuncios fraudulentos
Los perfiles falsos y las campañas maliciosas utilizan anuncios pagos como vector de ataque, aprovechando redes sociales y buscadores para promover estafas y páginas de phishing. Con la nueva pestaña Anuncios y Búsqueda Paga, Threat Hunting permite mapear estas campañas, identificar riesgos y actuar rápidamente.
-1.png?width=5412&height=3156&name=tela%20(1)-1.png)
La búsqueda permite filtrar señales mediante parámetros como:
adPublisherPlatform=FacebookDevuelve anuncios maliciosos publicados en una plataforma específica (por ejemplo: Facebook, Instagram o Threads).
metaProfileVerificationStatus=NOT_VERIFIEDIdentifica anuncios promovidos por perfiles falsos o no verificados, habituales en campañas fraudulentas.
adTitle="oferta imperdible"Busca patrones sospechosos en títulos de anuncios, útiles para identificar estafas comunes.
adDescription="..."Muestra descripciones interpretadas por IA, incluyendo el texto extraído de imágenes, lo que permite detectar anuncios disfrazados o creatividades sospechosas.
Estos filtros ayudan a su equipo a monitorear riesgos de phishing y fraude que se originan directamente en campañas pagas, un vector crítico para que los ataques ganen alcance y credibilidad.
Refinando la detección mediante colores predominantes
Además de los parámetros tradicionales, Threat Hunting ahora permite búsquedas por colores predominantes, una funcionalidad disponible tanto en la pestaña de URLs y Dominios como en Anuncios y Búsqueda Paga. Esta función facilita la identificación de páginas falsas y anuncios fraudulentos que utilizan la identidad visual de su marca, incluso sin mencionarla directamente.
Parámetros disponibles:
predominantColor=purpleBusca resultados donde el color predominante sea púrpura, útil para marcas o instituciones con identidades visuales reconocibles.
predominantColorHex=#E50914Busca un color específico mediante su código hexadecimal.
predominantColorRGB="[229, 9, 20]"Busca un color específico utilizando el código RGB.
Esta funcionalidad amplía la capacidad investigativa de equipos avanzados, revelando intentos sofisticados de fraude basados en elementos visuales, un diferenciador técnico poco común en el mercado, y refuerza la sofisticación de la herramienta.
Investigando incidentes
Al investigar un incidente de seguridad, puedes utilizar el Threat Hunting para saber si los atacantes usaron información expuesta para llevar a cabo su campaña. También puedes identificar si un incidente tiene el potencial de propagarse a otras partes de la red (debido a credenciales vinculadas, reutilización de contraseñas y otros riesgos).
Aquí hay algunos parámetros útiles para investigar incidentes de ciberseguridad:
- emailDomain=tuempresa.dominio.ejemplo.com
Localiza credenciales expuestas con el nombre de dominio de tu organización. También puedes utilizar el operador "O" para incluir dominios adicionales. - user=cuentacomprometida@tuempresa.dominio.ejemplo.com
Al igual que lo anterior, encuentra cualquier credencial expuesta perteneciente al usuario especificado. - password=contraseña
Al investigar intentos de acceso fallidos o sospechosos, también puedes usar este parámetro para descubrir si la contraseña utilizada en el intento de acceso se ha filtrado anteriormente.
Cabe destacar que, aunque puedes consultar estos datos proactivamente, la plataforma Axur puede alertar automáticamente sobre eventos de alto riesgo, como cuando una credencial corporativa puede estar comprometida. El Threat Hunting, como su nombre indica, brilla cuando estás activamente tratando de descubrir (o "cazar") datos de amenazas y encontrar la causa raíz de un incidente.
Vea el Threat Hunting en acción
Si deseas explorar más a fondo, puedes comenzar con nuestro plan gratuito y experimentar el poder del threat hunting de primera mano. Contáctanos — esperamos poder ayudarte a proteger tu negocio.